

Next: Grouping supermarket purchases by
Up: PHENOMENAL DATA MINING: FROM
Previous: Introduction
What phenomena in the world should a data mining program have built
into it, be told or be able to discover for itself?
At first,
knowledge of the general phenomena will be built into the data miners
(data mining programs), and the programs will infer specific values.
Later data miners should use the information expressed in a logical
form. This will permit them to use databases of common sense facts
about the world. Very ambitious data mining projects might hope to
make programs that will come up with entirely new phenomena.
Here are some phenomena and facts relevant to the supermarket domain
together with logical expressions for some of these facts. We give
just two example formulas, and these are not part of a worked out
scheme for constructing a knowledge base.
- people
- There are the shoppers themselves and also family
members. The data may not identify them directly, but learning
about them is the point of data mining.
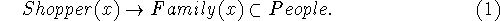
- ownership and purchases
- People buy things and then own them and
keep them somewhere. Maybe the facts about where people keep things
are not relevant for most data mining. The distinction between
durable goods and consumables is important. Here's a
situation calculus expression of two facts.
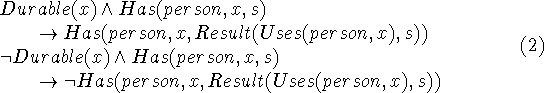
- possessions
- Freezers, refrigerators, cars and microwave ovens
are items that some customers will have and others won't. Having
them affects behavior.
- events
- The observed events are purchases in the stores for
which we have databases.
Unobserved are the trips to the store and the cooking and eating and
the inspections of the larder. Maybe these can usefully be
discriminated, but maybe they should be lumped into consumption.
Other unobserved events include purchases from the competitors.
When a person purchases a freezer, his status changes to that of a
freezer owner and that fact will persist. The event of acquiring a
freezer is more common than that of giving up the possession of a
freezer.
- preferences
- People have preferences among states of
affairs--or more specifically among objects.
- distributions of properties over people
- The customers have age,
sex, income and ethnic distributions.
- customers appear and disappear
- There are causes for the
appearance and disappearance of customers, and supermarket chains will
be interested in finding them out. These include moving in or out
of the area, change in family circumstances, advertising campaigns
by the chain or its competitors, changes in the store or its hours of
operation, satisfaction or dissatisfaction with goods, prices or
service.
The present state of AI is not up to formulating a full common sense
database, but full common sense knowledge is not necessary. We can
expect to do a lot with very limited knowledge. A sophisticated data
mining system might be able to use the following facts in its
formulation of hypotheses. An ambitious logic-based system might use
logical expressions of the facts. Less ambitiously, programmers would
use them in designing data mining systems.
- People persist in time. People want objects. People consume objects
and want more. Some objects are permanent on the relevant time scale.
- Objects are created, appear in stores, sold to customers (people) who
use them up and need more.
- There are kinds of people and kinds of objects.
- People have attributes, and these attributes change, although some are
permanent.
- People buy objects with money. This uses up money and people do not buy
at a rate much higher than they get more money.
- There is an is-a hierarchy of items and and an is-a hierarchy of
people. We suppose these are spelled out in some literature.
- There is an is-a hierarchy of food.
- Although it is tempting to organize facts into is-a hierarchies,
this is not always possible or appropriate. More complicated
predicates and functions and logical assertions are sometimes needed
to express the facts.
- People are associated into families. Purchases are made for a family.
- When food items are purchased, some go into pantries, some into
refrigerators, some into freezers and some are eaten right away.
When a food object is eaten it is removed from where it was stored.
- There are bounds on the rate at which people eat. What they don't get
from one store they get from another.
- A person has an age which increases with time. Very young people are
children.
- There are lots of people an lots of stores. The data miner will have
information about only some of them.
- Customers who buy substantial quantities of frozen or freezable
goods have freezers.
- Owners of microwave ovens can be identified.
- Consistent purchase of the most expensive items indicates
prosperity. It can be asked whether consistent purchase of
expensive items is all the data miner wants to know anyway. I don't
know about that.
- Suppose a customer comes rarely and always buys frozen spinach
in bags and a few other items. Inference: the store where he buys
most of his food doesn't sell frozen spinach in bags.
The point is that all the above are a priori facts that may be used to
infer phenomena. We suppose that only some phenomena need be taken into
account. For this phenomenal mining we ignore birth and death, physical
motion, and shape. Mass is taken into account only in connection with
quantities purchased and rates of consumption.
It is clear that a very large number of facts are relevant to getting
information out of databases of customer purchases. These include
general facts of common sense and specific facts about consumer
properties, consumer goods and consumer behavior. I see no
alternative to a big project like CyC, as described by
Lenat and Guha [Lenat and Guha 1990], for putting facts into
a knowledge base by hand. However even a small knowledge base may be
useful and adequate for experiments. Perhaps substantial parts of the
existing CyC knowledge base may provide part of the information needed
for supermarket phenomenal data mining.
Next: Grouping supermarket purchases by
Up: PHENOMENAL DATA MINING: FROM
Previous: Introduction
John McCarthy
Wed Feb 23 17:08:25 PST 2000